Project note
Chess-GPT: Teaching an LLM to Play Chess
Last year I supervised a bachelor’s thesis project by Aron Malmborg and Edwin Östlund at KTH, where they trained a transformer to play chess from scratch using only human game data. The result is Chess-GPT, a model that learns both the rules and strategy of chess purely through next-move prediction, with no explicit programming of chess knowledge whatsoever. You can play against it in your browser.
The project builds directly on Adam Karvonen’s Chess-GPT work, which showed that a transformer trained on PGN strings can learn an internal representation of the board state. Aron and Edwin’s focus was somewhat different: rather than probing the model’s internal representations, they were primarily interested in the playing style of the resulting model, and whether it would end up resembling human play more than existing chess engines like Stockfish.
Setup
The implementation is built on top of NanoGPT, Andrej Karpathy’s compact open-source reimplementation of a GPT-style language model. NanoGPT is essentially a clean, minimal GPT-2-style decoder-only transformer training stack: it takes a sequence of tokens, processes them with masked self-attention, and learns a conditional distribution for the next token. In its standard use case those tokens are pieces of text. Here, the same autoregressive setup is repurposed for chess.
Chess-GPT is then trained from scratch to predict the next move in a sequence of chess moves written in SAN notation. The key difference from Karvonen’s approach is the tokenisation scheme: rather than character-level tokens, each move is treated as a single token. This reduces the vocabulary to roughly 1,855 tokens and lets the model focus on game structure rather than spending capacity learning how chess move notation is spelt.
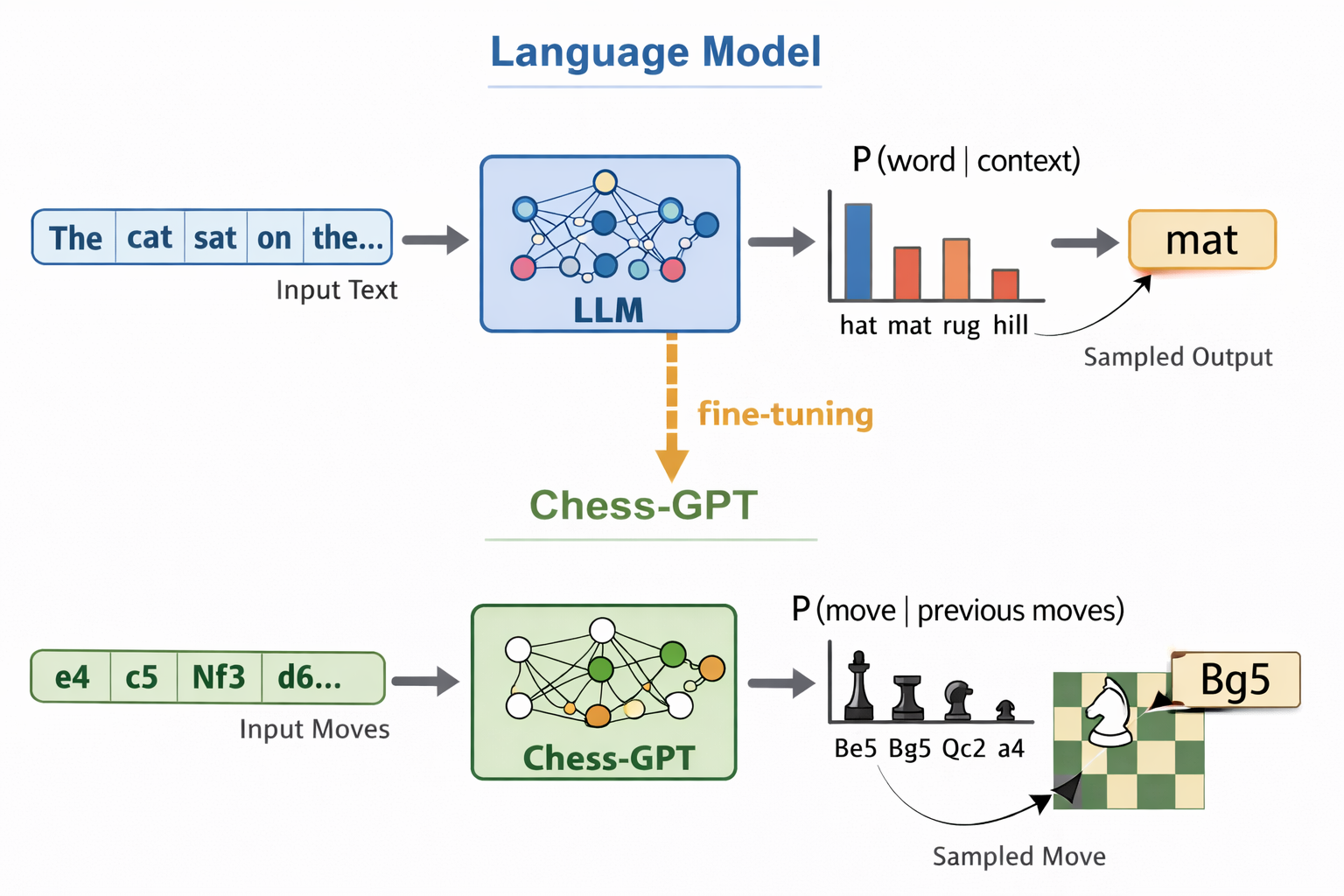
Two model sizes were trained, both with 8 attention heads and a 512-dimensional model:
| Model | Layers | Parameters |
|---|---|---|
| Chess-GPT-small | 8 | 26M |
| Chess-GPT-medium | 16 | 52M |
Training data came from the Lichess open database: 16 million human games with a mean player Elo of roughly 1650. The models were trained with AdamW and cosine annealing, with a context window of 256 tokens (enough for ~85 full moves, covering nearly all games in the dataset).
Learning the rules
One of the more striking results is how quickly the model picks up legality. After just 2,000 gradient steps, a tiny fraction of training, Chess-GPT-medium already plays legal moves more than 90% of the time. By the end of training it reaches 99.2% ± 0.1% on random out-of-distribution positions.

This suggests that the surface rules of chess (which piece can go where, what constitutes a legal move) are relatively easy to absorb from raw statistics, without any prior structure. What is harder, and where the model still falls short of human-level generalisation, is reliably handling the tail of unusual positions.
How well does it play?
Performance was measured by playing 1,000 games against Stockfish at its lowest skill level (Stockfish-0), then computing an Elo estimate from the win rate, anchored to an assumed Elo of 1300 for Stockfish-0.

| Model | Elo | Win rate vs. Stockfish-0 | Legal move rate |
|---|---|---|---|
| Chess-GPT-small | 1121 ± 25 | 25% | 98.7% |
| Chess-GPT-medium | 1198 ± 22 | 36% | 99.2% |
An Elo around 1200 is a solid casual club player, respectable for a model with no hard-coded chess knowledge. Looking at move quality more carefully, the typical Chess-GPT move is actually slightly better than Stockfish-0’s and comparable to the human games in the dataset (median centipawn loss of −11 cp vs. −16 cp for humans and −24 cp for Stockfish-0). The problem is in the tail: Chess-GPT blunders at a 14% rate, the same as Stockfish-0 and higher than the 11% seen in human games. The model loses games not from chronic mediocrity but from occasional catastrophic mistakes.
Does it play like a human?
This was the most interesting question, and the answer is a surprising no. To measure playing style, Aron and Edwin extracted move-frequency distributions from 100 games each of Chess-GPT, Stockfish-0, and human players, then computed pairwise Jensen-Shannon divergences.
| Comparison | Token JS-div. | Bigram JS-div. | Trigram JS-div. |
|---|---|---|---|
| Humans vs. Stockfish | 0.14 | 0.42 | 0.74 |
| Humans vs. Chess-GPT | 0.26 | 0.62 | 0.78 |
| Stockfish vs. Chess-GPT | 0.28 | 0.66 | 0.81 |
Chess-GPT ends up further from both humans and Stockfish than they are from each other, despite being trained exclusively on human games. Stockfish, which introduces artificial blunders to regulate its skill level, is actually closer to human play than Chess-GPT is. The model has developed its own idiosyncratic style, the source of which is unclear.
One hypothesis is that the model’s style reflects some strong inductive bias in its architecture or the particular patterns that are most useful for next-move prediction. Understanding what drives this divergence would require the kind of probing and activation analysis that Karvonen did, which would make a natural extension of this project.
Play against it
Aron and Edwin put together a browser demo so you can play against Chess-GPT yourself. It’s unlikely to beat a serious club player, but it plays interesting chess and occasionally pulls off moves that feel unexpectedly creative. Give it a try:
→ Play Chess-GPT in your browser
What’s next
The most natural extension is to add a reinforcement learning step after pre-training, rewarding wins rather than just next-move prediction accuracy. Because the model already internalises the rules and something of strategy, the RL fine-tuning should be far cheaper than training an RL chess agent from scratch, similar in spirit to how RLHF works on top of pre-trained language models.
Another direction is mechanistic interpretability. Karvonen showed that linear probes on Chess-GPT’s residual stream can reconstruct the board state with up to 99.6% accuracy, and that erasing a piece from the activation causes the model to treat it as absent when generating subsequent moves. It would be interesting to run the same analysis on Chess-GPT and see whether the internal board representation differs between the two tokenisation schemes, and whether probing could shed light on why the playing style diverges so strongly from human games.
The full write-up is available as a PDF: Chess-GPT: A Chess-Playing Transformer Model (Malmborg & Östlund, KTH, 2025).